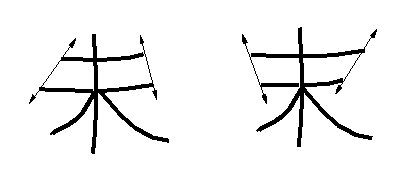
多くの文字認識手法の平均的な処理では、このように似通った文字の弁別は困難である。 "0−O"のように、全く同じ形状の文字パターンに対しては、 書き方規則で一方の字形を変えて対処する以外にない。しかし、 漢字のように字種が増えて来ると書き方規則を定めることは不可能である。 唯一の解決策は知識処理である。
全く同じ形状の場合は別として、"干−于"、"未−末" など、 類似した文字でも多少とも形状に相違した箇所があることが多い。 差異を区別できる特徴を音声学の用語を借りて弁別的特徴 (distinctive feature)と呼ぼう。 弁別的特徴を用い、入力文字が候補のどちらかであるかを判定するのが二段判定である。 弁別的特徴は、ある部分を拡大して差を見るので、 英語では Zooming と呼ぶのが適当であろうと思っている。
このような対に属する文字パターンは、全クラスを対象とする平均的な認識手法 (これを一段判定と呼ぼう) では近接リジェクト となるであろう (というか、近接リジェクトになっても良いから誤認識を起こさないようにパラメータ調整する)。
二段判定には、近接リジェクトとなった候補文字クラスが送られて来るが、 そのクラス数は少数 (多くの場合、二、三個) に限られる。 これらの文字クラスから2個のクラスを選び、その対のための二段判定 (識別に最適な特徴を用いる) によって勝ち抜き戦を行う。 この勝ち抜き戦は全てのクラスの対ごとに行う必要がある。 あるクラスが、他の全候補クラスに勝利を収めれば、そのクラスが認識結果である。
識別に使用される特徴は、文字クラスの対ごとに異なるであろう。 たとえば"干−于"であれば、縦棒の下端にハネがあるかどうかを見れば良いし、 "未−末"では、原理的には2本の横ストロークの長さを比較すれば良い。 実際には、横ストロークの抽出は困難なので、 次の概念図のように、横ストロークの端点を結ぶ直線のなす角度を計れば良いだろう。
場合によっては、いわゆる巴戦となって、結果が三すくみとなることもあり得る。 この場合は、どの文字クラスもどこかの勝負で負けている筈なので、認識結果にはなり得ない。 結局、二段判定の結果も近接リジェクトになる。
上の説明では、1クラスに1個しか標準パターン (文字概念) がないとして説明したが、 現実はもう少し複雑である。一段判定から候補として、 あるクラスの標準パターン複数個を送り出して来ることがあり得るからである。 したがって、二段判定は文字クラスというより、標準パターン (に代表されるサブクラス) の間で行う。 同一クラスに属する標準パターンの間では二段判定は行うと、 おかしなことになる場合があるので注意が必要である。
二段判定は、近接リジェクトに関係しない文字クラスの認識率には一切影響しない。 取り敢えずリジェクトにしておいて、設計者の手の空いたときに対策することも、 場合によっては不可能ではない。したがって、適切に行えば必ず認識率は必ず上昇し、 効果は絶大である。しかし、工数 (しかも、文字認識に熟練した技術者の工数) が必要となることが欠点である。 また、英数字程度では全てのクラス対に用意することは不可能ではないが、 漢字のように文字クラスが多くなると実現は困難になる。
数字認識システムに漢字"乙"や"己"が入って来たとき、 これを"2"と判定してしまうことは良くあることである。 認識アルゴリズム設計者の立場からは、これは当然のことであっても、利用者から見ると、 このような誤読が起きると装置の信頼性を著しく損なう。
実は、"乙"→"2"と誤読しても、利用者には納得して貰える。 しかし、"R"→"4"や、"∞"→"8"など、人間では起こり得ないような誤読が起きると、 利用者は OCR がいい加減なことをやっているのではないかと疑念を抱いてしまう。
このため、検定という概念が導入された。 検定とは、認識結果があるクラス"X"であったとして、 真に入力パターンが"X"であるかを調べ直す処理をいう。 具体的には、いくつか特徴パラメータの値が、 そのクラスの定義範囲に入っているかどうかを調べることによって行う。
図は数字"2"の認識システムが漢字"乙"をはじくための検定処理の概念図である。 右上隅と左下隅の曲率のそれぞれが許容範囲に入っていることを確認すれば良い。
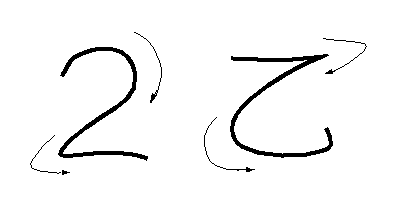
ある意味では、検定はナンセンスと言える。 入力パターンが"X"であることが真に確認できる特徴があるならば、 その特徴を一段判定で使用してしまえば良いからである。 検定が必要なのは、認識技術が未熟である証拠だとも言える。
一方では検定にも弁護意見がある。 すなわち、入力パターンがクラス"X"であることを言うための特徴は "X"ごとに異なるであろう。 そのような千差万別の特徴を一般的な認識アルゴリズムに含めるのは得策ではなく、 汎用的な手法によって候補を確定したあとで、 その候補クラスに特有な処理を行う方が有利であるという主張である。
実際の検定処理では、入力パターンがクラス"X"であることを積極的に主張するのは難しい。
もちろん、やってできないことはないがリジェクトが圧倒的に増える。
したがって、"X"は持たず "X"以外のクラスが持つ特徴がもしあれば、
"X"ではないと考えてリジェクトする処理になる。
(検定処理に入って来たときは候補クラスは一つに確定しているので、
このクラスを否定すればリジェクトになる。)
直ちに想像されるように、これは簡単ではない。
ある入力パターンが"2"以外のクラスでないことをいうには、数字だけの世界では解決できない。
数字以外のパターンが入って来たとき、それが数字ではないことを言わないといけない。
例えば、英字"Z"、漢字"乙"、"己"が入って来たとき、
"2"を認識結果としないようにしなければならない。
これだけでも大変な努力であるが、世界にはギリシャ文字、キリル文字、ヘブライ文字、
アラビア文字、タイ文字、デーヴァナーガリ文字、等々と枚挙に暇がない。
文字以外の図形やノイズが入力されることもありえる。
あらゆる方向への誤読を行わないようにするのは極めて困難である。
ただ、数字程度に限定すると、
誤読の対象となるパターンは英字・記号・カタカナなどで現れることが多く、
これらの混合セットでの二段判定を利用して検定を実現できることが多い。
検定は、その文字クラス以外の文字クラスの認識率には影響せず、 適切に行えば確実に誤読が減るし、間違えたところでリジェクトが増えるだけなので、 努力の甲斐がある処理である。しかし、二段判定と同じく熟練技術者の工数が必要となる。
参考文献
←[手書き文字認識]
←[中野の研究紹介]
←[中野の目次]
| mail address: |  |
← お手数ですが打ち込んで下さい |
First Written February 2, 1999
Transplanted to KSU Before June 20, 2003
Divided June 20, 2003
Transplanted to So-net May 4, 2005
Last Update July 11, 2005