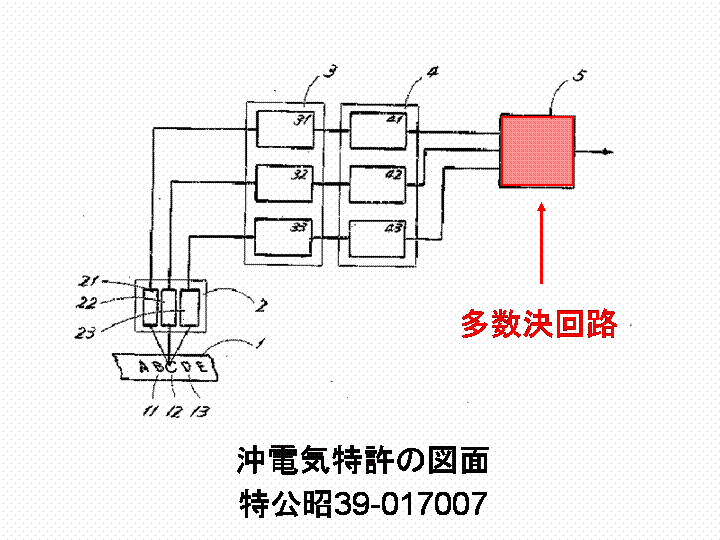
問題は、このアイデアがどの程度有効かである。
University of Nevada, Las Vegas は、
市販されていた複数の印刷英字 OCR について認識率のデータを求めるとともに、
多数決によって画期的に認識率が上がることを示した。
日本の郵政研究所でも、手書き数字に関する複数の OCR の認識結果の多数決によって、
認識率が上昇することを示した。
ところが、印刷日本語 OCR についてはこのような報告はない。
そこで市販されている 6種類の OCR について、同一の
JEIDA 文書画像データベースを対象サンプルとして認識させたところ、
個々の OCR の認識率 97.29%-99.19% が 99.59% に向上した。
特に、湧き出し・消失など、切り出し不良に基づく誤りが大きく減ることは特筆される。
詳細については下記第一論文参照。
この論文の実験では 1,476文字とサンプル数が少かったが、
その後 17文書、9,775字にサンプルを増やして追実験した。
その結果、6種類の OCR の認識率 91.30%-98.10% が 99.33% に改良されることが判った。
それでは、ソフトウェア OCR なら実用化できるかというとそうとも言えない。 University of Nevada, Las Vegas の実験も、われわれの実験も、 OCR で読ませるべき領域の指定 (zoning) を手動でやっているからである。 いくら OCR の価格が安いからといって、領域指定をオペレータがやるのでは、 手間がかかって仕方ないし、指定を機種ごと間違える危険もある。
かといって領域指定を各 OCR の自動領域切り出しに任せたのでは、 領域指定能力が全く違うので、関係ない領域の文字を対応付けることになって、 これまた意味を持たない。
下記の第二の論文は、OCR の自動領域切り出し結果を比較し、 最適の領域対応付けを自動的に行うことを追求したものである。
| mail address: |  |
← お手数ですが打ち込んで下さい |
First Written February 2, 1999
Transplanted to KSU Before May 16, 2003
Transplanted to So-net May 4, 2005
Last Update April 22, 2007
© Yasuaki Nakano 1999-2007