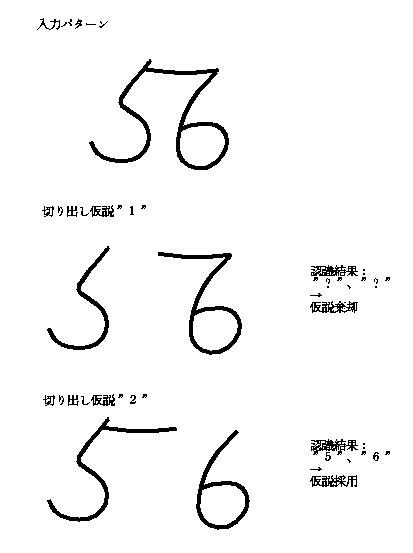
文字切り出しは認識の前処理と考えられ、従来は軽視されていた。しかし、 切り出しは実は認識の問題であり、極めて重要なことを指摘した。 手書き英数字を対象として、重なり・接触の場合を含めて切り出しを可能とする技術 「多重仮説検定法」を開発した。
この方法では、切り出し部で複数の仮説を立てる。 認識部では、その仮説に従った文字パターンを認識するが、妙なところで切り出すと、 認識結果はリジェクトとなる筈である(そのためには、認識部の性能が高い必要がある)。 認識部でリジェクトされない切り出し仮説を採用することにより、 切り出しと認識が同時に得られる。例を示す。
この技術は世界で "oversegmentation" と呼ばれることがある。 「多重仮説検定法」という名前が難し過ぎて通用していないのは残念である。
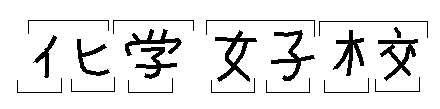
実例を挙げれば、「化学」や「女子校」という単語(横書き)が入力されたとき、 切り出し部では「へん」や「つくり」を独立の文字として切り出す可能性があり、 これは認識部では排除することができない。 したがって、「イヒ学」とか「好校」「女子木交」という認識結果が正しいものと誤認され得る。 単語認識も協調させ、単語として受理される切り出し仮説が正しい切り出しだったこととすれば、 この問題は解決できる。
この原理の特許はかなり早い時期に出願したが、実際の研究着手は遅れた。 そのため、研究発表は東芝、日電、NTT(オンライン文字認識)などが先である。 郵便区分機の住所読み取りでは、恐らくこの技術は必須であるので、 特許が成立することを願っている。
[追記]
疑問を持たれる方もおられるかも知れないので追記しておく。
厳密に言えば「旧中山道」はともかく「1日中山道」は単語ではないが、
複合語認識も単語認識に含めて考えることができる。
「女子校」は単語かどうか疑問があることは承知しており、 「女子高」はあるが「女子校」なんかない、という突っ込みは却下。
| mail address: |  |
← お手数ですが打ち込んで下さい |
First Written Before January 10, 1995
Transplanted to KSU Before June 20, 2003
Transplanted to So-net May 4, 2005
Last Update July 11, 2005